1. pandas 개요
pandas는 데이타 분석(Data Analysis)을 위해 널리 사용되는 파이썬 라이브러리 패키지이다. pandas는 과학용 파이썬 배포판인 아나콘다(Anaconda)에 기본적으로 제공되지만, 아나콘다를 사용하지 않을 경우에는 pip install pandas 를 통해 설치할 수 있다. 이 아티클에서는 pandas의 기본적인 개념과 기초적인 샘플들을 소개한다.
2. pandas 사용법
pandas를 사용하기 위해서는 먼저 pandas를 아래와 같이 import 한다. pandas는 크게 세가지의 자료구조를 지원하고 있는데, 1차원 자료구조인 Series, 2차원 자료구조인 DataFrame, 그리고 3차원 자료구조인 Panel을 지원한다.
Series
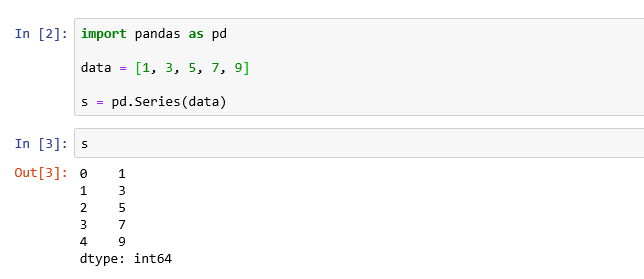
가장 간단한 1차원 자료구조인 Series는 배열/리스트와 같은 일련의 시퀀스 데이타를 받아들이는데, 별도의 인덱스 레이블을 지정하지 않으면 자동적으로 0부터 시작되는 디폴트 정수 인덱스를 사용한다.
import pandas as pd data = [1, 3, 5, 7, 9] s = pd.Series(data)
DataFrame
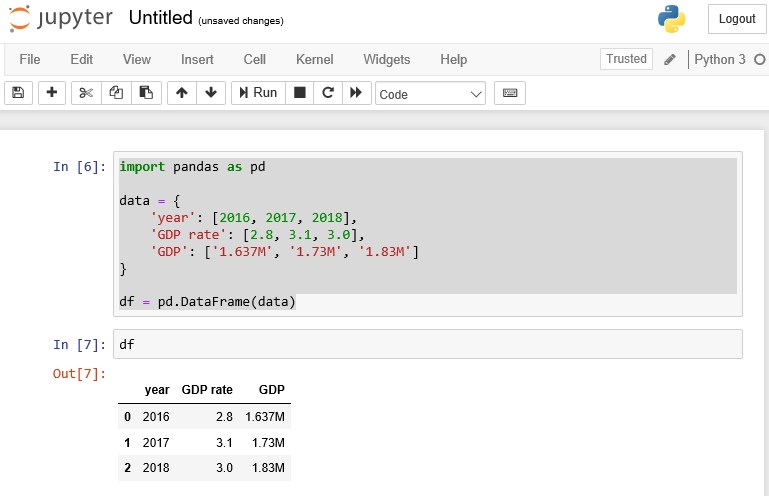
2차원 자료구조인 DataFrame는 행과 열이 있는 테이블 데이타(Tabular Data)를 받아들이는데, 아래 예제는 그 한가지 방법으로서 열(column)을 dict의 Key로, 행(row)을 dict의 Value로 한 Dictionary 데이타를 pd.DataFrame()을 사용하여 pandas의 Data Frame 자료구조로 변환한 예이다.
import pandas as pd
data = {
'year': [2016, 2017, 2018],
'GDP rate': [2.8, 3.1, 3.0],
'GDP': ['1.637M', '1.73M', '1.83M']
}
df = pd.DataFrame(data)
Panel
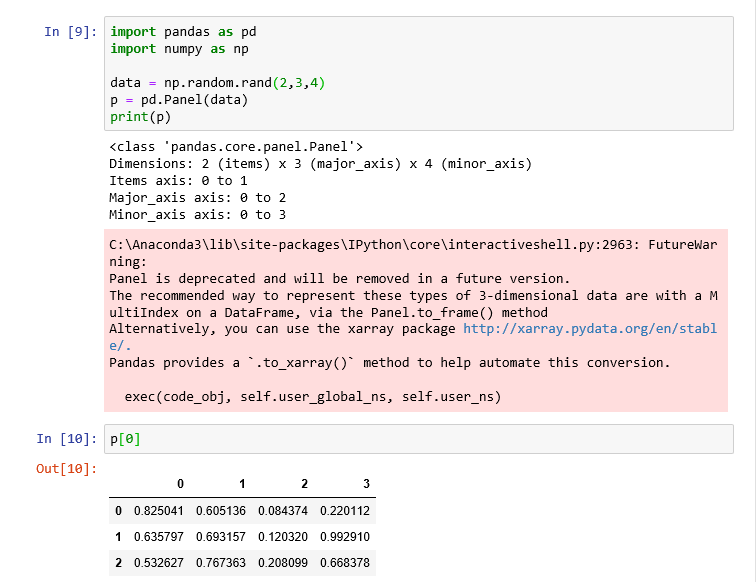
3차원 자료구조인 Panel은 Axis 0 (items), Axis 1 (major_axis), Axis 2 (minor_axis) 등 3개의 축을 가지고 있는데, Axis 0은 그 한 요소가 2차원의 DataFrame 에 해당되며, Axis 1은 DataFrame의 행(row)에 해당되고, Axis 2는 DataFrame의 열(column)에 해당된다.
아래 예제는 numpy를 사용하여 3차원 난수를 발생시킨 후, 이를 pandas.Panel() 에 적용한 예이다. 출력 결과에 보면, 2 (items) x 3 (major_axis) x 4 (minor_axis) 크기의 Panel 객체가 생성되었음을 알 수 있다. Panel 객체 p로부터 p[0]을 조회하면, Axis 0 의 첫번째 요소인 DataFrame이 출력됨을 볼 수 있다.
3. 데이타 엑세스
pandas에서 Series, DataFrame, Panel 등의 자료구조를 만든 후, 다양한 방법을 통해
데이타를 엑세스할 수 있다.
가장 간단한 방식으로 pandas 자료구조에 대해 인덱싱 혹은 속성(Attribute)을 사용하는 것인데, 예를 들어
위에서 생성한 DataFrame인 df 에 대해 year 행을 가져오기 위해 df["year"] 혹은 df.year 를 사용할 수 있다.
또한, 부울린 인덱싱 (boolean indexing)을 사용하여 특정 조건의 데이타만 필터링 할 수도 있는데,
df[df['year'] > 2016]은 2016년 초과인 데이타만 필터링해서 표시한다.
데이타량이 많은 경우는 df.head() 함수를 사용하면 처음 5개 row를 표시해 주며, df.tail() 함수를 사용하면 마찬가지로 마지막 5개 row를 표시해 준다.
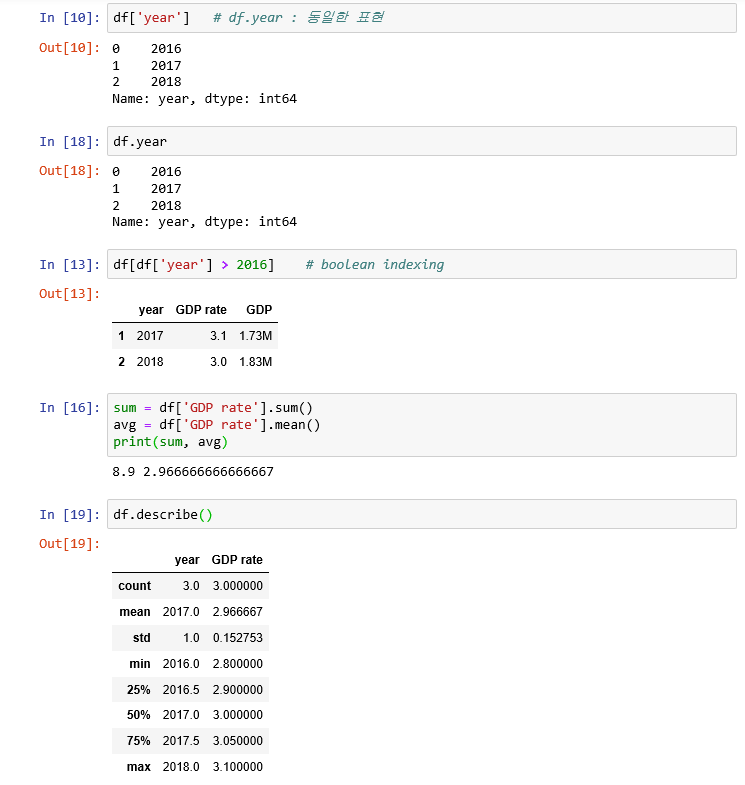
pandas는 데이타에 대한 다양한 연산 함수들을 제공하고 있는데, 예를 들어 합계 구하는 sum(), 평균을 구하는 mean(), 최소를 구하는 min(), 최대를 구하는 max() 등을 사용할 수 있다. 또한, 위 그림에서 보듯이, 기본적인 통계치를 모두 표시하기 위해 describe() 함수를 사용할 수 있다.
4. 외부 데이타 읽고 쓰기
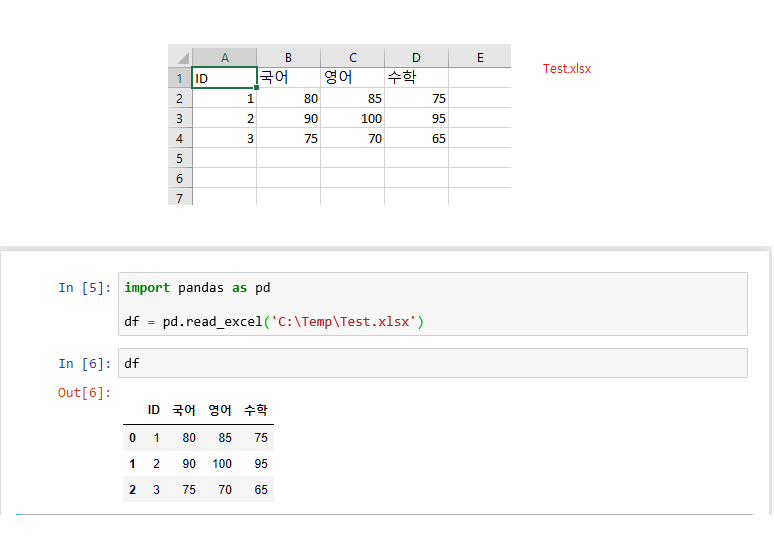
pandas는 CSV 파일, 텍스트 파일, 엑셀 파일, SQL 데이타베이스, HDF5 포맷 등 다양한 외부 리소스에 데이타를 읽고 쓸 수 있는 기능을 제공한다. 아래 예제는 엑셀 파일파일로부터 데이타를 읽어 오는 기능을 예시한 것이다.
그리고, CSV 파일을 읽고 쓰기 위해서는 아래와 같이 read_csv() 와 to_csv() 함수를 사용할 수 있다.
import pandas as pd
df = pd.read_csv('C:\Temp\Test.csv') # csv 읽기
df.to_csv('C:\Temp\Output.csv') # csv 쓰기
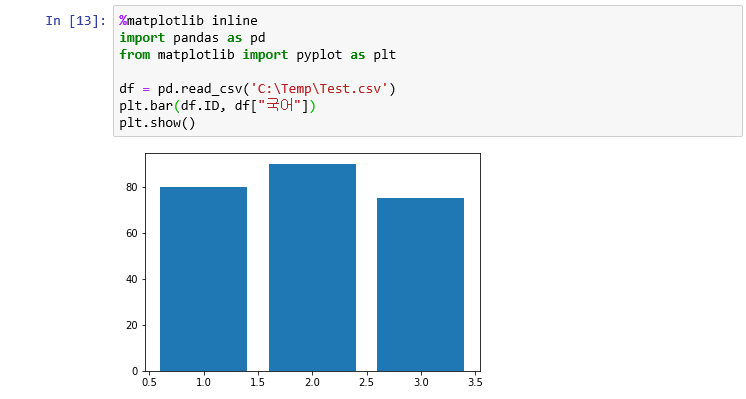
아래 예제는 CSV 파일 데이타를 pandas를 통해 읽어 들인 후, matplotlib 을 통해 Bar 차트를 그리는 예이다.